
Wikipedia, YouTube, Reddit: which platforms actually get cited by LLMs?
A look into where each AI model looks for answers, and where you should be putting your content.


One of the most frustrating things about optimizing for AI search, as you’ve noticed, is that the rules aren’t the same across models – like the headache of figuring out Google’s ever-opaque algorithm, multiplied by how many models you’re tracking. Gemini cites one set of sources. ChatGPT pulls from somewhere else entirely. AI companies lagging behind have made partnerships with brands to try and get their time in the limelight, with some massively backfiring.
Which means the old SEO instinct – build great content on your own domain, wait to rank, optimize if not – doesn’t fully translate. In the GEO era, which platforms you publish on matters almost as much as the content itself. And the answer depends on which model you’re trying to be cited by.
We’ve been digging into this from two angles.
The first is our own study on whether Google’s AI favors YouTube, where we ran 180 queries across Gemini, Claude, and ChatGPT to test how often each model cites Google’s own video platform.
The second is Ahrefs’ analysis of the most mentioned domains in AI assistants – a much wider sample of 78.6 million searches across AI Overviews, ChatGPT, and Perplexity. (Note: the Ahrefs data is from June 2025, so the specific share percentages have almost certainly shifted by now, but the structural patterns are still the most useful starting point we have.)
Together, they give us a fairly clear picture of where each model goes for answers and which platform could prop your brand even further.
Gemini has a YouTube problem (or preference)
The cleanest signal in our research came from looking at how often each model cited YouTube across 60 distinct queries, run in English, French, and Polish.
Across all queries and languages, Gemini cited YouTube in 21.7% of its responses. Claude came in second at roughly 11%. ChatGPT was a distant third at around 3%.
Gemini, a Google product, has a clear bias for YouTube, a Google-acquired platform. Surprise!
But things got more interesting when we broke it down by language. In English, Claude and Gemini cited YouTube at the exact same rates, 16.7% each.

Yet as soon as the queries shifted to French and Polish, their behavior diverged sharply. Gemini’s YouTube citations increased in non-English languages, while Claude’s decreased. The gap between the two models grew from zero in English to nearly 25 percentage points in Polish.
If Gemini were citing YouTube simply because it’s a better source for certain query types, you’d expect its behavior to stay relatively stable across languages. Instead, it leans into YouTube more heavily as queries move into non-English territory – which is the pattern you’d predict if the model had been tuned to favor a property owned by its parent company. Google has not confirmed this anywhere (hey, neither are we), and we can only observe citation behavior rather than the underlying mechanism. But the pattern is hard to explain on content quality alone.
There’s one important caveat we’d be remiss not to mention. When we asked Gemini and Claude to explicitly list sources at the end of the prompt (the same instruction we had to add for ChatGPT, which doesn’t cite spontaneously), both models cited YouTube far less. That suggests a chunk of those spontaneous YouTube citations are functionally “further reading” embeds rather than sources the model actually drew from to build its answer.
This is an important nuance to keep in mind when trying to interpret citation data: there’s a difference between being embedded and being consulted. The ideal is, to of course, have both, and the pendulum between what’s more important may swing either way as AI search continues to evolve.
What gets cited everywhere else
Our data zeroed in on YouTube alone, which is where Ahrefs’ study complements this breakdown. Its analysis widens the lens to the top 10 most-cited domains across each model, and the meat of it is in the variation between models.
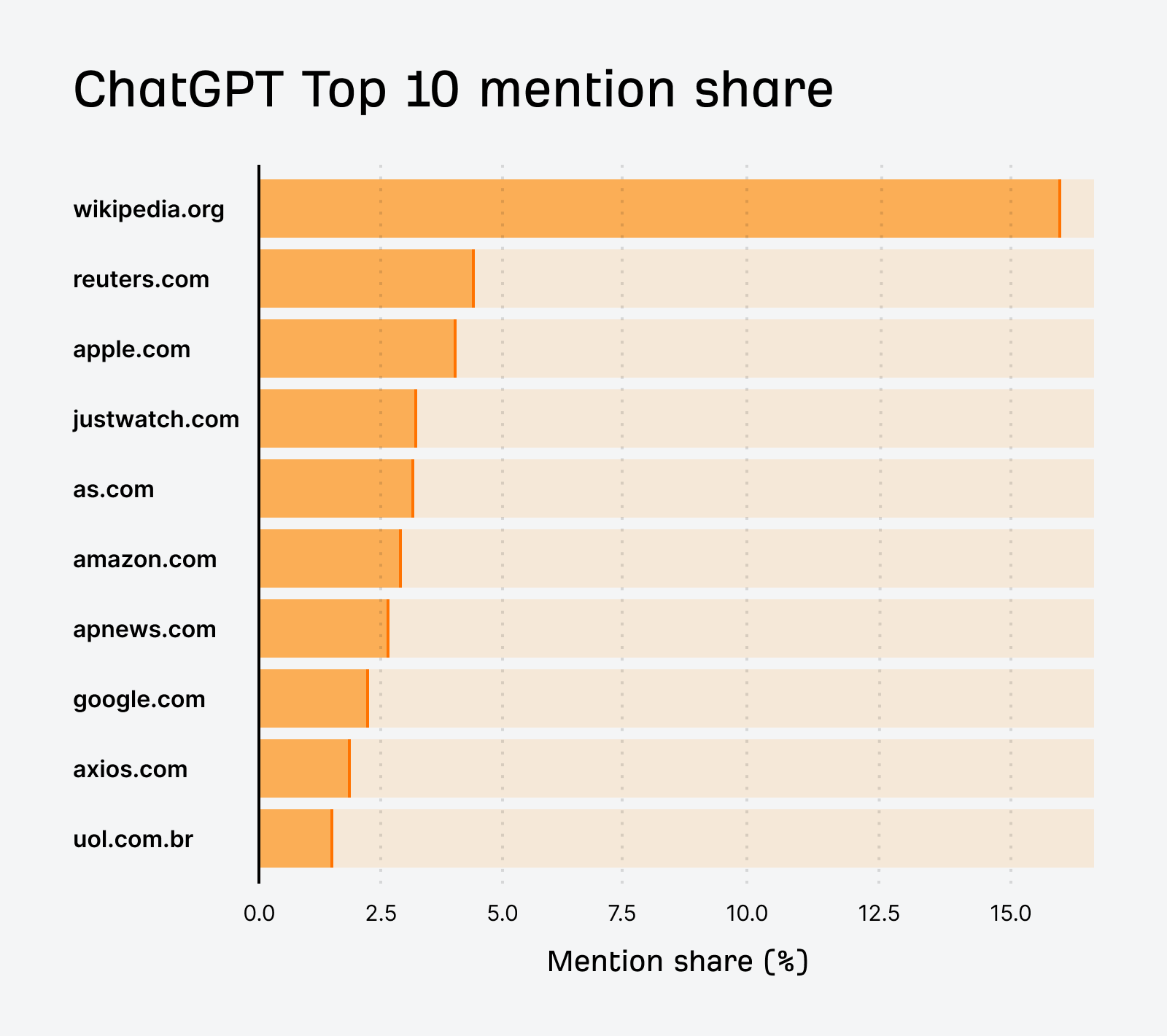
ChatGPT’s top sources lean heavily on Wikipedia (16.3% mention share – the highest of any model on any single platform), then a long tail of news outlets and major brands: Reuters, Apple, JustWatch, AS.com, Amazon, AP News, Google, Axios, and the Brazilian portal UOL. Notably, YouTube doesn’t crack ChatGPT’s top 10 at all, though this may be explained by ChatGPT’s tendency not to cite sources explicitly. The LLM also pulls heavily from developer documentation (developer.mozilla.org, docs.docker.com) and Arxiv when queries get technical, which are patterns that don’t show up in the same way for the other models.
AI Overviews’ top sources look more like the “open web” composite you’d expect Google to surface: Wikipedia (8.4%), YouTube (9.5%), Reddit (7.4%), Quora (3.6%), translate.google.com (a quietly significant 3.3%), then a cluster of health authorities – Healthline, Mayo Clinic, Cleveland Clinic, NIH, Medical News Today. Reddit and Quora’s prominence here shows how differently these AI search platforms work, as they don’t make the top 10 in either ChatGPT or Perplexity. Potential explanation: Google appears to weight user-generated content far more heavily than its competitors.
Perplexity shares the broad strokes – Wikipedia at the top, YouTube a close second at 16.1%. But it tends to surface more niche specialist sites, particularly in health, with Ahrefs flagging tuasaude and alodokter as examples.
So which platforms should you actually prioritize?
A model-by-model translation of the above:
If you want to be cited by ChatGPT, the most defensible plays are getting onto Wikipedia (genuinely difficult – their editorial standards are notoriously strict, and we speak from experience), being mentioned in major news outlets like Reuters and AP, and – for technical content – building authoritative documentation. Video doesn’t help you here, at least not yet. Easier said than done, but that seems to be the playbook today.
If you want to be cited by Google’s AI Overviews, the picture is closer to traditional SEO with a community-content twist. Wikipedia presence helps, but so does meaningful activity on Reddit and Quora. For consumer health, education, or any category where authority matters, the established institutional sites dominate. And YouTube remains a strong bet, particularly for tutorial-style content. The SEO specialists on LinkedIn yelling “traditional SEO isn’t dead! It’s what gets you cited in LLMs!” are right, and you should listen to them. They’re also really good at catching company websites exploiting AI to manipulate rankings and put them on blast.
If you want to be cited by Perplexity, Wikipedia and YouTube are your two highest-leverage moves. Perplexity also rewards niche specialist authority more than the other models, which means a well-positioned vertical site can punch above its weight here.
If you want to be cited by Gemini, YouTube is the standout opportunity. Both because of Gemini’s apparent structural (or nepotistic) preference for the platform and because the citation rate is highest for tutorial content, where YouTube has a genuine quality argument anyway. Our data showed Claude ranked YouTube at an average position of 3.6 when it cited it; Gemini at 4.3. If you produce educational or how-to video content, YouTube remains your darling angel.
And for your international marketing?
There’s one platform implication that matters specifically for brands operating across languages, and it’s the part of our research that surprised us most.
Gemini’s YouTube preference intensifies in non-English markets. So if you’re competing for visibility in French, Polish, German, or any non-English query environment, Gemini is materially more likely to surface video answers than its competitors are.
That has two practical implications. The first is that brands operating internationally should weigh their YouTube investment more heavily in non-English markets than they might in English ones.
The second is the harder pill to swallow. If Gemini routes users toward YouTube in your category, you’re competing for AI visibility against the platform itself and not just against direct competitors.
This sits alongside a finding we’ve been writing about for a while: when localized content is scarce, AI models don’t simply skip your market. They find substitutes, and this could be you, or your competitors. In another study we did, we found that Google AI Overviews translated English sources to fill local content gaps in 8% of queries overall, and 17% in tech categories. Which platform you should prioritize is, at its core, a multilingual question: which platforms each model cites in your target language is what determines whether your brand gets surfaced at all.
Answer engines aren’t a monolith
If you zoom out, the per-model data tells one consistent story: AI assistants are not a single channel. They’re three (or more) very differently shaped distribution systems, each with its own structural preferences, each rewarding a slightly different content strategy.
But make no mistake: the brands that survive the AI tidal waves of disruption over the next few years aren’t the ones who pick the “right” platform, and we caution against this. Instead, they’re the ones who understand which platforms each model is structurally biased toward, and place strategic bets accordingly, particularly for the languages and markets where they need visibility most.
We’re going to keep digging into this. If there’s a model, language, or content category you’d like us to test next, let us know.